| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|





|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
This chapter introduces execution plans, describes the SQL command EXPLAIN PLAN,
and explains how to interpret its output. This chapter also provides
procedures for managing outlines to control application performance
characteristics.
This chapter contains the following sections:
| See Also:
Oracle9i SQL Reference for the syntax of |
The EXPLAIN PLAN statement displays execution plans chosen by the Oracle optimizer for SELECT, UPDATE, INSERT, and DELETE statements. A statement's execution plan is the sequence of operations Oracle performs to run the statement.
The row source tree is the core of the execution plan. It shows the following information:
In addition to the row source tree, the plan table contains information about the following:
The EXPLAIN PLAN results let
you determine whether the optimizer selects a particular execution
plan, such as, nested loops join. It also helps you to understand the
optimizer decisions, such as why the optimizer chose a nested loops
join instead of a hash join, and lets you understand the performance of
a query.
|
Note: Oracle Performance Manager charts and Oracle SQL Analyze can automatically create and display explain plans for you. For more information on using explain plans, see Database Tuning with the Oracle Tuning Pack. |
With the cost-based optimizer, execution plans can and do change as the underlying costs change. EXPLAIN PLAN
output shows how Oracle runs the SQL statement when the statement was
explained. This can differ from the plan during actual execution for a
SQL statement, because of differences in the execution environment and
explain plan environment.
Execution plans can differ due to the following:
Even if the schemas are the same, the optimizer can choose different execution plans if the costs are different. Some factors that affect the costs include the following:
Examining an explain plan lets you look for throw-away in cases such as the following:
For example, in the following explain plan, the last step is a very unselective range scan that is executed 76563 times, accesses 11432983 rows, throws away 99% of them, and retains 76563 rows. Why access 11432983 rows to realize that only 76563 rows are needed?
Rows Execution Plan -------- ---------------------------------------------------- 12 SORT AGGREGATE 2 SORT GROUP BY 76563 NESTED LOOPS 76575 NESTED LOOPS 19 TABLE ACCESS FULL CN_PAYRUNS_ALL 76570 TABLE ACCESS BY INDEX ROWID CN_POSTING_DETAILS_ALL 76570 INDEX RANGE SCAN (object id 178321) 76563 TABLE ACCESS BY INDEX ROWID CN_PAYMENT_WORKSHEETS_ALL 11432983 INDEX RANGE SCAN (object id 186024)
The execution plan operation alone cannot differentiate
between well-tuned statements and those that perform poorly. For
example, an EXPLAIN PLAN output that shows
that a statement uses an index does not necessarily mean that the
statement runs efficiently. Sometimes indexes can be extremely
inefficient. In this case, you should examine the following:
It is best to use EXPLAIN PLAN
to determine an access plan, and then later prove that it is the
optimal plan through testing. When evaluating a plan, examine the
statement's actual resource consumption. Use Oracle Trace or the SQL
trace facility and TKPROF to examine individual SQL statement performance.
| See Also:
Chapter 10, "Using SQL Trace and TKPROF" for information on TKPROF interpretation |
Before issuing an EXPLAIN PLAN statement, you must have a table to hold its output. PLAN_TABLE is the default sample output table into which the EXPLAIN PLAN statement inserts rows describing execution plans. Use the SQL script UTLXPLAN.SQL to create the PLAN_TABLE in your schema. The exact name and location of this script depends on your operating system. On Unix, it is located in the $ORACLE_HOME/rdbms/admin directory.
For example, run the commands in Example 9-2 from a SQL*Plus session to create the PLAN_TABLE in the HR schema.
CONNECT HR/your_password
@$ORACLE_HOME/RDBMS/ADMIN/UTLXPLAN.SQL
Table created.
Oracle Corporation recommends that you drop and rebuild the PLAN_TABLE table after upgrading the version of the database because the columns might change. This can cause scripts to fail or cause TKPROF to fail, if you are specifying the table.
If you want an output table with a different name, then create PLAN_TABLE and rename it with the RENAME SQL statement.
To explain a SQL statement, use the following:
EXPLAIN PLAN FOR SQL_Statement
For example:
EXPLAIN PLAN FOR SELECT last_name FROM employees;
This explains the plan into the PLAN_TABLE table. You can then select the execution plan from PLAN_TABLE. This is useful if you do not have any other plans in PLAN_TABLE, or if you only want to look at the last statement.
With multiple statements, you can specify a statement
identifier and use that to identify your specific execution plan.
Before using SET STATEMENT ID, remove any existing rows for that statement ID.
In Example 9-3, bad1 is specified as the statement identifier:
EXPLAIN PLAN SET STATEMENT_ID = 'bad1' FOR SELECT last_name FROM employees;
You can specify the INTO clause to specify a different table.
EXPLAIN PLAN INTO my_plan_table FOR SELECT last_name FROM employees;
You can specify a statement Id when using the INTO clause.
EXPLAIN PLAN INTO my_plan_table SET STATEMENT_ID = 'bad1' FOR SELECT last_name FROM employees;
| See Also:
Oracle9i SQL Reference for a complete description of |
After you have explained the plan, use the two scripts provided by Oracle to display the most recent plan table output:
UTLXPLS.SQL - Shows plan table output for serial processingUTLXPLP.SQL - Shows plan table output with parallel execution columnsExample 1-4, "EXPLAIN PLAN Output" is an example of the plan table output when using the UTLXPLS.SQL script.
If you have specified a statement identifier, then you can write your own script to query the PLAN_TABLE. For example:
STATEMENT_ID.CONNECT BY clause to walk the tree from parent to child, the join keys being STATEMENT_ID = PRIOR STATEMENT_ID and PARENT_ID = PRIOR ID.LEVEL (associated with CONNECT BY) to indent the children.
SELECT cardinality "Rows", lpad(' ',level-1)||operation||' '|| options||' '||object_name "Plan" FROM PLAN_TABLE CONNECT BY prior id = parent_id AND prior statement_id = statement_id START WITH id = 0 AND statement_id = 'bad1' ORDER BY id; Rows Plan ------- ---------------------------------------- SELECT STATEMENT TABLE ACCESS FULL EMPLOYEES
The NULL in the Rows column indicates that the optimizer does not have any statistics on the table. Analyzing the table shows the following:
Rows Plan ------- ---------------------------------------- 16957 SELECT STATEMENT 16957 TABLE ACCESS FULL EMPLOYEES
You can also select the COST. This is useful for comparing execution plans or for understanding why the optimizer chooses one execution plan over another.
This section uses progressively complex examples to illustrate execution plans.
The statement in Example 9-5 is used to display the execution plan.
SELECT lpad(' ',level-1)||operation||' '||options||' '|| object_name "Plan" FROM plan_table CONNECT BY prior id = parent_id AND prior statement_id = statement_id START WITH id = 0 AND statement_id = '&1' ORDER BY id;
The following are EXPLAIN PLAN examples.
EXPLAIN PLAN SET statement_id = 'example_plan1' FOR SELECT full_name FROM per_all_people_f WHERE UPPER(full_name) LIKE 'Pe%' ; Plan --------------------------------------------- SELECT STATEMENT TABLE ACCESS FULL PER_ALL_PEOPLE_F
This plan shows execution of a SELECT statement. The table per_all_people_f is accessed using a full table scan.
per_all_people_f is accessed, and the WHERE clause criteria is evaluated for every row.SELECT statement returns the rows meeting the WHERE clause criteria.EXPLAIN PLAN SET statement_id = 'example_plan2' FOR SELECT full_name FROM per_all_people_f WHERE full_name LIKE 'Pe%' ; Plan --------------------------------------------- SELECT STATEMENT TABLE ACCESS BY INDEX ROWID PER_ALL_PEOPLE_F INDEX RANGE SCAN PER_PEOPLE_F_N54
This plan shows execution of a SELECT statement.
per_people_f_n54 is used in a range scan operation.per_all_people_f is accessed through ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE
clause conditions that could not be evaluated during the range scan
(because the column is present in the table and not in the index) are
also evaluated.SELECT statement returns rows satisfying the WHERE clause conditions (evaluated in previous steps).EXPLAIN PLAN SET statement_id = 'example_plan3' FOR SELECT segment1, segment2, description, inventory_item_id FROM mtl_system_items msi WHERE segment1 = :b1 AND segment2 LIKE '%-BOM' AND NVL(end_date_active,sysdate+1) > SYSDATE ; Plan -------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY INDEX ROWID MTL_SYSTEM_ITEMS INDEX RANGE SCAN MTL_SYSTEM_ITEMS_N8
This plan shows execution of a SELECT statement.
mtl_system_items_n8 is used in a range scan operation. This is an index on (segment1, segment2, segment3). The range scan happens using the following condition:
segment1=:b1
The rows that come out of this step satisfy all the WHERE
clause criteria that can be evaluated with the index columns.
Therefore, the following condition is also evaluated at this stage:
segment2 LIKE '%-BOM'
per_all_people_f is accessed through ROWIDs obtained from the index in the previous step. When the table is accessed, any additional WHERE
clause conditions that could not be evaluated during the range scan
(because the column is present in the table and not in the index) are
also evaluated. Therefore, the following condition is evaluated at this
stage: NVL(end_date_active,sysdate+1) > SYSDATE
SELECT statement returns rows satisfying the WHERE clause conditions (evaluated in previous steps).EXPLAIN PLAN SET statement_id = 'example_plan4' FOR SELECT h.order_number, l.revenue_amount, l.ordered_quantity FROM so_headers_all h, so_lines_all l WHERE h.customer_id = :b1 AND h.date_ordered > SYSDATE-30 AND l.header_id = h.header_id ; Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N1 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
This plan shows execution of a SELECT statement.
so_headers_n1 is used in a range scan operation. This is an index on customer_id. The range scan happens using the following condition:
customer_id = :b1
so_headers_all is accessed through ROWIDs obtained from the index in the previous step. When the table is accessed, any additional WHERE
clause conditions that could not be evaluated during the range scan
(because the column is present in the table and not in the index) are
also evaluated. Therefore, the following condition is evaluated at this
stage: h.date_ordered > sysdate-30
so_headers_all satisfying the WHERE clause conditions, a range scan is run on so_lines_n1 using the following condition:
l.header_id = h.header_id
so_lines_all is accessed through ROWIDs obtained from the index in the previous step. When the table is accessed, any additional WHERE
clause conditions that could not be evaluated during the range scan
(because the column is present in the table and not in the index) are
also evaluated. There are no additional conditions to evaluate here.SELECT statement returns rows satisfying the WHERE clause conditions (evaluated in previous steps).Index row sources using bitmap indexes appear in the EXPLAIN PLAN output with the word BITMAP indicating the type of the index. Consider the sample query and plan in Example 9-10.
EXPLAIN PLAN FOR SELECT * FROM t WHERE c1 = 2 AND c2 <> 6 OR c3 BETWEEN 10 AND 20;SELECT STATEMENT TABLE ACCESS T BY INDEX ROWID BITMAP CONVERSION TO ROWID BITMAP OR BITMAP MINUS BITMAP MINUS BITMAP INDEX C1_IND SINGLE VALUE BITMAP INDEX C2_IND SINGLE VALUE BITMAP INDEX C2_IND SINGLE VALUE BITMAP MERGE BITMAP INDEX C3_IND RANGE SCAN
In this example, the predicate c1=2 yields a bitmap from which a subtraction can take place. From this bitmap, the bits in the bitmap for c2 = 6 are subtracted. Also, the bits in the bitmap for c2 IS NULL are subtracted, explaining why there are two MINUS row sources in the plan. The NULL subtraction is necessary for semantic correctness unless the column has a NOT NULL constraint. The TO ROWIDS option is used to generate the ROWIDs that are necessary for the table access.
|
Note: Queries using bitmap join index indicate the bitmap join index access path. The operation for bitmap join index is the same as bitmap index. |
Use EXPLAIN PLAN to see how Oracle accesses partitioned objects for specific queries.
Partitions accessed after pruning are shown in the PARTITION START and PARTITION STOP columns. The row source name for the range partition is PARTITION RANGE. For hash partitions, the row source name is PARTITION HASH.
A join is implemented using partial partition-wise join if the DISTRIBUTION column of the plan table of one of the joined tables contains PARTITION(KEY).
Partial partition-wise join is possible if one of the joined tables is
partitioned on its join column and the table is parallelized.
A join is implemented using full partition-wise join if the partition row source appears before the join row source in the EXPLAIN PLAN
output. Full partition-wise joins are possible only if both joined
tables are equi-partitioned on their respective join columns. Examples
of execution plans for several types of partitioning follow.
Consider the following table, emp_range, partitioned by range on hire_date to illustrate how pruning is displayed. Assume that the tables emp and dept from a standard Oracle schema exist.
CREATE TABLE emp_range PARTITION BY RANGE(hire_date) ( PARTITION emp_p1 VALUES LESS THAN (TO_DATE('1-JAN-1991','DD-MON-YYYY')), PARTITION emp_p2 VALUES LESS THAN (TO_DATE('1-JAN-1993','DD-MON-YYYY')), PARTITION emp_p3 VALUES LESS THAN (TO_DATE('1-JAN-1995','DD-MON-YYYY')), PARTITION emp_p4 VALUES LESS THAN (TO_DATE('1-JAN-1997','DD-MON-YYYY')), PARTITION emp_p5 VALUES LESS THAN (TO_DATE('1-JAN-1999','DD-MON-YYYY'))) AS SELECT * FROM employees;
For the first example, consider the following statement:
EXPLAIN PLAN FOR SELECT * FROM emp_range;
Enter the following to display the EXPLAIN PLAN output:
@?/RDBMS/ADMIN/UTLXPLS
Oracle displays something similar to the following:
Plan Table ------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart | Pstop| ------------------------------------------------------------------------------- | SELECT STATEMENT | | 105 | 8K| 1 | | | | PARTITION RANGE ALL | | | | | 1 | 5 | | TABLE ACCESS FULL |EMP_RANGE | 105 | 8K| 1 | 1 | 5 | ------------------------------------------------------------------------------- 6 rows selected.
A partition row source is created on top of the table
access row source. It iterates over the set of partitions to be
accessed. In this example, the partition iterator covers all partitions
(option ALL), because a predicate was not used for pruning. The PARTITION_START and PARTITION_STOP columns of the PLAN_TABLE show access to all partitions from 1 to 5.
For the next example, consider the following statement:
EXPLAIN PLAN FOR SELECT * FROM emp_range WHERE hire_date >= TO_DATE('1-JAN-1995','DD-MON-YYYY'); Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart| Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | 3 | 54 | 1 | | | | PARTITION RANGE ITERATOR | | | | | 4 | 5 | | TABLE ACCESS FULL |EMP_RANGE | 3 | 54 | 1 | 4 | 5 | -------------------------------------------------------------------------------- 6 rows selected.
In the previous example, the partition row source
iterates from partition 4 to 5, because we prune the other partitions
using a predicate on hire_date.
Finally, consider the following statement:
EXPLAIN PLAN FOR SELECT * FROM emp_range WHERE hire_date < TO_DATE('1-JAN-1991','DD-MON-YYYY'); Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart| Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | 2 | 36 | 1 | | | | TABLE ACCESS FULL |EMP_RANGE | 2 | 36 | 1 | 1 | 1 | -------------------------------------------------------------------------------- 5 rows selected.
In the previous example, only partition 1 is accessed and known at compile time; thus, there is no need for a partition row source.
Oracle displays the same information for hash partitioned objects, except the partition row source name is PARTITION HASH instead of PARTITION RANGE. Also, with hash partitioning, pruning is only possible using equality or IN-list predicates.
To illustrate how Oracle displays pruning information for composite partitioned objects, consider the table emp_comp that is range partitioned on hire_date and subpartitioned by hash on department_id.
CREATE TABLE emp_comp PARTITION BY RANGE(hire_date) SUBPARTITION BY HASH(department_id) SUBPARTITIONS 3 ( PARTITION emp_p1 VALUES LESS THAN (TO_DATE('1-JAN-1991','DD-MON-YYYY')), PARTITION emp_p2 VALUES LESS THAN (TO_DATE('1-JAN-1993','DD-MON-YYYY')), PARTITION emp_p3 VALUES LESS THAN (TO_DATE('1-JAN-1995','DD-MON-YYYY')), PARTITION emp_p4 VALUES LESS THAN (TO_DATE('1-JAN-1997','DD-MON-YYYY')), PARTITION emp_p5 VALUES LESS THAN (TO_DATE('1-JAN-1999','DD-MON-YYYY'))) AS SELECT * FROM employees;
For the first example, consider the following statement:
EXPLAIN PLAN FOR SELECT * FROM emp_comp; Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart | Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | 105 | 8K| 1 | | | | PARTITION RANGE ALL | | | | | 1 | 5 | | PARTITION HASH ALL | | | | | 1 | 3 | | TABLE ACCESS FULL |EMP_COMP | 105 | 8K| 1 | 1 | 15| -------------------------------------------------------------------------------- 7 rows selected.
This example shows the plan when Oracle accesses all subpartitions of all partitions of a composite object. Two partition row sources are used for that purpose: a range partition row source to iterate over the partitions and a hash partition row source to iterate over the subpartitions of each accessed partition.
In the following example, the range partition row source iterates from partition 1 to 5, because no pruning is performed. Within each partition, the hash partition row source iterates over subpartitions 1 to 3 of the current partition. As a result, the table access row source accesses subpartitions 1 to 15. In other words, it accesses all subpartitions of the composite object.
EXPLAIN PLAN FOR SELECT * FROM emp_comp
WHERE hire_date = TO_DATE('15-FEB-1997', 'DD-MON-YYYY');
Plan Table
--------------------------------------------------------------------------------
| Operation | Name | Rows | Bytes| Cost | Pstart| Pstop |
--------------------------------------------------------------------------------
| SELECT STATEMENT | | 1 | 96 | 1 | | |
| PARTITION HASH ALL | | | | | 1 | 3 |
| TABLE ACCESS FULL |EMP_COMP | 1 | 96 | 1 | 13 | 15 |
--------------------------------------------------------------------------------
6 rows selected.
In the previous example, only the last partition,
partition 5, is accessed. This partition is known at compile time, so
we do not need to show it in the plan. The hash partition row source
shows accessing of all subpartitions within that partition; that is,
subpartitions 1 to 3, which translates into subpartitions 13 to 15 of
the emp_comp table.
Now consider the following statement:
EXPLAIN PLAN FOR SELECT * FROM emp_comp WHERE department_id = 20; Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart| Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | 2 | 200 | 1 | | | | PARTITION RANGE ALL | | | | | 1 | 5 | | TABLE ACCESS FULL |EMP_COMP | 2 | 200 | 1 | | | -------------------------------------------------------------------------------- 6 rows selected.
In the previous example, the predicate deptno
= 20 enables pruning on the hash dimension within each partition, so
Oracle only needs to access a single subpartition. The number of that
subpartition is known at compile time, so the hash partition row source
is not needed.
Finally, consider the following statement:
VARIABLE dno NUMBER; EXPLAIN PLAN FOR SELECT * FROM emp_comp WHERE department_id = :dno; Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart| Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | 2 | 200 | 1 | | | | PARTITION RANGE ALL | | | | | 1 | 5 | | PARTITION HASH SINGLE | | | | | KEY | KEY | | TABLE ACCESS FULL |EMP_COMP | 2 | 200 | 1 | | | -------------------------------------------------------------------------------- 7 rows selected.
The last two examples are the same, except that deptno = 20 has been replaced by department_id = :dno.
In this last case, the subpartition number is unknown at compile time,
and a hash partition row source is allocated. The option is SINGLE for that row source, because Oracle accesses only one subpartition within each partition. The PARTITION_START and PARTITION_STOP is set to KEY. This means that Oracle determines the number of the subpartition at run time.
In the following example, emp_range is joined on the partitioning column and is parallelized. This enables use of partial partition-wise join, because the dept table is not partitioned. Oracle dynamically partitions the dept table before the join.
ALTER TABLE emp PARALLEL 2; Table altered.ALTER TABLE dept PARALLEL 2;
Table altered.
To show the plan for the query, enter:
EXPLAIN PLAN FOR SELECT /*+ ORDERED USE_HASH(D) */ ename, dname FROM emp_range e, dept d WHERE e.deptno = d.deptno AND e.hire_date > TO_DATE('29-JUN-1996','DD-MON-YYYY');
Plan Table ------------------------------------------------------------------------------------------------------------ | Operation | Name | Rows | Bytes| Cost | TQ |IN-OUT| PQ Distrib | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------ | SELECT STATEMENT | | 1 | 51 | 3 | | | | | | | HASH JOIN | | 1 | 51 | 3 | 2,02 | P->S |QC (RANDOM) | | | | PARTITION RANGE ITERATOR | | | | | 2,02 | PCWP | | 4 | 5 | | TABLE ACCESS FULL |EMP_RANGE | 3 | 87 | 1 | 2,00 | PCWP | | 4 | 5 | | TABLE ACCESS FULL |DEPT | 21 | 462 | 1 | 2,01 | P->P |PART (KEY) | | | ------------------------------------------------------------------------------------------------------------ 8 rows selected.
The plan shows that the optimizer selects partition-wise join, because the PQ Distrib column contains the text PART (KEY), or partition key.
In the next example, emp_comp is joined on its hash partitioning column, deptno, and is parallelized. This enables use of partial partition-wise join, because the dept table is not partitioned. Again, Oracle dynamically partitions the dept table.
ALTER TABLE emp_comp PARALLEL 2; Table altered.EXPLAIN PLAN FOR SELECT /*+ ORDERED USE_HASH(D) */ ename, dname
FROM emp_comp e, dept d WHERE e.deptno = d.deptno AND e.hiredate > TO_DATE('13-MAR-1995','DD-MON-YYYY');
Plan Table ------------------------------------------------------------------------------------------------------------ | Operation | Name | Rows | Bytes| Cost | TQ |IN-OUT| PQ Distrib | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------ | SELECT STATEMENT | | 1 | 51 | 3 | | | | | | | HASH JOIN | | 1 | 51 | 3 | 0,01 | P->S | QC (RANDOM)| | | | PARTITION RANGE ITERATOR | | | | | 0,01 | PCWP | | 4 | 5 | | PARTITION HASH ALL | | | | | 0,01 | PCWP | | 1 | 3 | | TABLE ACCESS FULL |EMP_COMP | 3 | 87 | 1 | 0,01 | PCWP | | 10 | 15 | | TABLE ACCESS FULL |DEPT | 21 | 462 | 1 | 0,00 | P->P | PART (KEY) | | | ------------------------------------------------------------------------------------------------------------ 9 rows selected.
In the following example, emp_comp and dept_hash are joined on their hash partitioning columns. This enables use of full partition-wise join. The PARTITION HASH row source appears on top of the join row source in the plan table output.
To create the table dept_hash, enter:
CREATE TABLE dept_hash PARTITION BY HASH(deptno) PARTITIONS 3 PARALLEL AS SELECT * FROM dept;
To show the plan for the query, enter:
EXPLAIN PLAN FOR SELECT /*+ ORDERED USE_HASH(D) */ ename, dname FROM emp_comp e, dept_hash d WHERE e.deptno = d.deptno
AND e.hiredate > TO_DATE('29-JUN-1996','DD-MON-YYYY');
Plan Table ------------------------------------------------------------------------------------------------------------ | Operation | Name | Rows | Bytes| Cost | TQ |IN-OUT| PQ Distrib | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------ | SELECT STATEMENT | | 2 | 102| 2 | | | | | | | PARTITION HASH ALL | | | | | 4,00| PCWP | | 1 | 3 | | HASH JOIN | | 2 | 102 | 2 | 4,00| P->S | QC (RANDOM)| | | | PARTITION RANGE ITERATOR | | | | | 4,00| PCWP | | 4 | 5 | | TABLE ACCESS FULL |EMP_COMP | 3 | 87 | 1 | 4,00| PCWP | | 10 | 15 | | TABLE ACCESS FULL |DEPT_HASH | 63 | 1K| 1 | 4,00| PCWP | | 1 | 3 | ------------------------------------------------------------------------------------------------------------ 9 rows selected.
An INLIST ITERATOR operation appears in the EXPLAIN PLAN output if an index implements an IN-list predicate. For example:
SELECT * FROM emp WHERE empno IN (7876, 7900, 7902);
The EXPLAIN PLAN output appears as follows:
OPERATION OPTIONS OBJECT_NAME ---------------- --------------- -------------- SELECT STATEMENT INLIST ITERATOR TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN EMP_EMPNO
The INLIST ITERATOR operation iterates over the next operation in the plan for each value in the IN-list predicate. For partitioned tables and indexes, the three possible types of IN-list columns are described in the following sections.
If the IN-list column empno is an index column but not a partition column, then the plan is as follows (the IN-list operator appears before the table operation but after the partition operation):
OPERATION OPTIONS OBJECT_NAME PARTITION_START PARTITION_STOP ---------------- ------------ ----------- --------------- -------------- SELECT STATEMENT PARTITION RANGE ALL KEY(INLIST) KEY(INLIST) INLIST ITERATOR TABLE ACCESS BY LOCAL INDEX ROWID EMP KEY(INLIST) KEY(INLIST) INDEX RANGE SCAN EMP_EMPNO KEY(INLIST) KEY(INLIST)
The KEY(INLIST) designation for the partition start and stop keys specifies that an IN-list predicate appears on the index start/stop keys.
If empno is an indexed and a partition column, then the plan contains an INLIST ITERATOR operation before the partition operation:
OPERATION OPTIONS OBJECT_NAME PARTITION_START PARTITION_STOP ---------------- ------------ ----------- --------------- -------------- SELECT STATEMENT INLIST ITERATOR PARTITION RANGE ITERATOR KEY(INLIST) KEY(INLIST) TABLE ACCESS BY LOCAL INDEX ROWID EMP KEY(INLIST) KEY(INLIST) INDEX RANGE SCAN EMP_EMPNO KEY(INLIST) KEY(INLIST)
If empno is a partition column and there are no indexes, then no INLIST ITERATOR operation is allocated:
OPERATION OPTIONS OBJECT_NAME PARTITION_START PARTITION_STOP ---------------- ------------ ----------- --------------- -------------- SELECT STATEMENT PARTITION RANGE INLIST KEY(INLIST) KEY(INLIST) TABLE ACCESS FULL EMP KEY(INLIST) KEY(INLIST)
If emp_empno is a bitmap index, then the plan is as follows:
OPERATION OPTIONS OBJECT_NAME ---------------- --------------- -------------- SELECT STATEMENT INLIST ITERATOR TABLE ACCESS BY INDEX ROWID EMP BITMAP CONVERSION TO ROWIDS BITMAP INDEX SINGLE VALUE EMP_EMPNO
You can also use EXPLAIN PLAN to derive user-defined CPU and I/O costs for domain indexes. EXPLAIN PLAN displays these statistics in the OTHER column of PLAN_TABLE.
For example, assume table emp has user-defined operator CONTAINS with a domain index emp_resume on the resume column, and the index type of emp_resume supports the operator CONTAINS. Then the query:
SELECT * FROM emp WHERE CONTAINS(resume, 'Oracle') = 1
might display the following plan:
OPERATION OPTIONS OBJECT_NAME OTHER ----------------- ----------- ------------ ---------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP DOMAIN INDEX EMP_RESUME CPU: 300, I/O: 4
Tuning a parallel query begins much like a non-parallel
query tuning exercise by choosing the driving table. However, the rules
governing the choice are different. In the non-parallel case, the best
driving table is typically the one that produces fewest number of rows
after limiting conditions are applied. The small number of rows are
joined to larger tables using non-unique indexes. For example, consider
a table hierarchy consisting of CUSTOMER, ACCOUNT, and TRANSACTION.
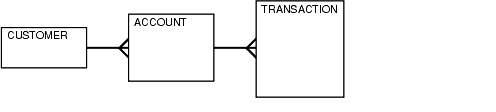
CUSTOMER is the smallest table while TRANSACTION
is the largest. A typical OLTP query might be to retrieve transaction
information about a particular customer's account. The query would
drive from the CUSTOMER table. The goal in this case is
to minimize logical I/O, which typically minimizes other critical
resources including physical I/O and CPU time.
For parallel queries, the choice of the driving table is
usually the largest table since parallel query can be utilized.
Obviously, it would not be efficient to use parallel query on the this
query, because only a few rows from each table are ultimately accessed.
However, what if it were necessary to identify all customers that had
transactions of a certain type last month? It would be more efficient
to drive from the TRANSACTION table since there are no limiting conditions on the customer table. The rows from the TRANSACTION table would be joined to the ACCOUNT table, and finally to the CUSTOMER table. In this case, the indexes utilized on the ACCOUNT and CUSTOMER
table are likely to be highly selective primary key or unique indexes,
rather than non-unique indexes used in the first query. Since the TRANSACTION table is large and the column is un-selective, it would be beneficial to utilize parallel query driving from the TRANSACTION table.
Parallel operation ------------------------------ PARALLEL_TO_SERIAL PARALLEL_TO_PARALLEL PARALLEL_COMBINED_WITH_PARENT PARALLEL_FROM_SERIAL PARALLEL_COMBINED_WITH_PARENT PARALLEL_TO_PARALLEL
PARALLEL_TO_PARALLEL operations generally produce the best performance as long as the workloads in each step are relatively equivalent.
A PARALLEL_COMBINED_WITH_PARENT operation occurs when the step is performed simultaneously with the parent step.
A PARALLEL_TO_SERIAL operation which is
always the step that occurs when rows from a parallel operation are
consumed by the query coordinator. Another type of operation that does
not occur in this query is a SERIAL operation. If these
types of operations occur, consider making them parallel operations to
improve performance since they too are potential bottlenecks.
If a parallel step produces many rows, the query coordinator may not be able to consume them as fast as they are being produced. There is little that can be done to improve this.
Every database operation uses the CPU. In most cases, CPU utilization is as important as I/O; often it is the only contribution to the cost (in cases of in-memory sort, hash, predicate evaluation, and cached I/O). In Oracle9i the optimizer introduces a new model, which includes the cost of CPU utilization. Including CPU utilization in the cost model helps generate better plans.
According to the CPU costing model:
Cost = (#SRds * sreadtim + #MRds * mreadtim + #CPUCycles / cpuspeed ) / sreadtim
where:
#SRDs is the number of single block reads#MRDs is the number of multi block reads#CPUCycles is the number of CPU Cycles *)sreadtim is the single block read timemreadtim is the multi block read timecpuspeed is the CPU cycles per secondCPUCycles includes CPU cost of query processing (pure CPU cost) and CPU cost of data retrieval (CPU cost of the buffer cache get).
This model is straightforward for serial execution. For
parallel execution, necessary adjustments are made while computing
estimates for #SRD, #MRD, and #CPUCycles.
Oracle does not support EXPLAIN PLAN for statements performing implicit type conversion of date bind variables. With bind variables in general, the EXPLAIN PLAN output might not represent the real execution plan.
From the text of a SQL statement, TKPROF cannot determine the types of the bind variables. It assumes that the type is CHARACTER,
and gives an error message if this is not the case. You can avoid this
limitation by putting appropriate type conversions in the SQL statement.
The PLAN_TABLE used by the EXPLAIN PLAN statement contains the columns listed in Table 9-1.
| Column | Type | Description |
|---|---|---|
|
|
|
Value of the optional |
|
|
|
Date and time when the |
|
|
|
Any comment (of up to 80 bytes) you want to associate
with each step of the explained plan. If you need to add or change a
remark on any row of the |
|
|
|
Name of the internal operation performed in this step. In the first row generated for a statement, the column contains one of the following values: See Table 9-4 for more information on values for this column. |
|
|
|
A variation on the operation described in the See Table 9-4 for more information on values for this column. |
|
|
|
Name of the database link used to reference the object (a table name or view name). For local queries using parallel execution, this column describes the order in which output from operations is consumed. |
|
|
|
Name of the user who owns the schema containing the table or index. |
|
|
|
Name of the table or index. |
|
|
|
Number corresponding to the ordinal position of the object as it appears in the original statement. The numbering proceeds from left to right, outer to inner with respect to the original statement text. View expansion results in unpredictable numbers. |
|
|
|
Modifier that provides descriptive information about the object; for example, |
|
|
|
Current mode of the optimizer. |
|
|
|
Not currently used. |
|
|
|
A number assigned to each step in the execution plan. |
|
|
|
The ID of the next execution step that operates on the output of the |
|
|
|
For the first row of output, this indicates the optimizer's estimated cost of executing the statement. For the other rows, it indicates the position relative to the other children of the same parent. |
|
|
|
Cost of the operation as estimated by the optimizer's
cost-based approach. For statements that use the rule-based approach,
this column is null. Cost is not determined for table access
operations. The value of this column does not have any particular unit
of measurement; it is merely a weighted value used to compare costs of
execution plans. The value of this column is a function of the |
|
|
|
Estimate by the cost-based approach of the number of rows accessed by the operation. |
|
|
|
Estimate by the cost-based approach of the number of bytes accessed by the operation. |
|
|
|
Contents of the |
|
|
|
Start partition of a range of accessed partitions. It can take one of the following values: n indicates that the start partition has been identified by the SQL compiler, and its partition number is given by n.
|
|
|
|
Stop partition of a range of accessed partitions. It can take one of the following values: n indicates that the stop partition has been identified by the SQL compiler, and its partition number is given by n.
|
|
|
|
Step that has computed the pair of values of the |
|
|
|
Other information that is specific to the execution step that a user might find useful. |
|
|
|
Method used to distribute rows from producer query servers to consumer query servers. See Table 9-3 for more information on the possible values for this column. For more information about consumer and producer query servers, see Oracle9i Data Warehousing Guide. |
|
|
|
CPU cost of the operation as estimated by the optimizer's cost-based approach. For statements that use the rule-based approach, this column is null. The value of this column is proportional to the number of machine cycles required for the operation. |
|
|
|
I/O cost of the operation as estimated by the optimizer's cost-based approach. For statements that use the rule-based approach, this column is null. The value of this column is proportional to the number of data blocks read by the operation. |
|
|
|
Temporary space, in bytes, used by the operation as estimated by the optimizer's cost-based approach. For statements that use the rule-based approach, or for operations that don't use any temporary space, this column is null. |
Table 9-2 describes the values that can appear in the OTHER_TAG column.
Table 9-3 describes the values that can appear in the DISTRIBUTION column:
Table 9-4 lists each combination of OPERATION and OPTION produced by the EXPLAIN PLAN statement and its meaning within an execution plan.
| Operation | Option | Description |
|---|---|---|
|
|
|
Operation accepting multiple sets of rowids, returning the intersection of the sets, eliminating duplicates. Used for the single-column indexes access path. |
|
|
|
|
|
|
|
|
|
|
|
Merges several bitmaps resulting from a range scan into one bitmap. |
|
|
|
Subtracts bits of one bitmap from another. Row source is used for negated predicates. Can be used only if there are nonnegated predicates yielding a bitmap from which the subtraction can take place. An example appears in "Viewing Bitmap Indexes with EXPLAIN PLAN". |
|
|
|
Computes the bitwise |
|
|
|
Computes the bitwise |
|
|
|
Takes each row from a table row source and finds the
corresponding bitmap from a bitmap index. This set of bitmaps are then
merged into one bitmap in a following |
|
|
|
Retrieves rows in hierarchical order for a query containing a |
|
|
|
Operation accepting multiple sets of rows returning the union-all of the sets. |
|
|
|
Operation counting the number of rows selected from a table. |
|
|
Count operation where the number of rows returned is limited by the |
|
|
|
|
Retrieval of one or more rowids from a domain index. The options column contain information supplied by a user-defined domain index cost function, if any. |
|
|
|
Operation accepting a set of rows, eliminates some of them, and returns the rest. |
|
|
|
Retrieval of only the first row selected by a query. |
|
|
|
Operation retrieving and locking the rows selected by a query containing a |
|
(These are join operations.) |
|
Operation joining two sets of rows and returning the result. This join method is useful for joining large data sets of data (DSS, Batch). The join condition is an efficient way of accessing the second table. CBO uses the smaller of the two tables/data sources to build a hash table on the join key in memory. Then it scans the larger table, probing the hash table to find the joined rows. |
|
|
|
Hash anti-join. |
|
|
|
Hash semi-join. |
|
(These are access methods.) |
|
Retrieval of a single rowid from an index. |
|
|
|
Retrieval of one or more rowids from an index. Indexed values are scanned in ascending order. |
|
|
|
Retrieval of one or more rowids from an index. Indexed values are scanned in descending order. |
|
|
|
Retrieval of all rowids from an index when there is no start or stop key. Indexed values are scanned in ascending order. |
|
|
|
Retrieval of all rowids from an index when there is no start or stop key. Indexed values are scanned in descending order. |
|
|
|
Retrieval of all rowids (and column values) using multiblock reads. No sorting order can be defined. Compares to a full table scan on only the indexed columns. Only available with the cost based optimizer. |
|
|
|
Retrieval of rowids from a concatenated index without using the leading column(s) in the index. Introduced in Oracle9i. Only available with the cost based optimizer. |
|
|
|
Iterates over the next operation in the plan for each value in the |
|
|
|
Operation accepting two sets of rows and returning the intersection of the sets, eliminating duplicates. |
|
(These are join operations.) |
|
Operation accepting two sets of rows, each sorted by a specific value, combining each row from one set with the matching rows from the other, and returning the result. |
|
|
|
Merge join operation to perform an outer join statement. |
|
|
|
Merge anti-join. |
|
|
|
Merge semi-join. |
|
|
|
Can result from 1 or more of the tables not having any
join conditions to any other tables in the statement. Can occur even
with a join and it may not be flagged as |
|
|
|
Retrieval of rows in hierarchical order for a query containing a |
|
|
|
Operation accepting two sets of rows and returning rows appearing in the first set but not in the second, eliminating duplicates. |
|
(These are join operations.) |
|
Operation accepting two sets of rows, an outer set and an inner set. Oracle compares each row of the outer set with each row of the inner set, returning rows that satisfy a condition. This join method is useful for joining small subsets of data (OLTP). The join condition is an efficient way of accessing the second table. |
|
|
|
Nested loops operation to perform an outer join statement. |
|
|
|
Access one partition. |
|
|
|
Access many partitions (a subset). |
|
|
|
Access all partitions. |
|
|
|
Similar to iterator, but based on an |
|
|
Indicates that the partition set to be accessed is empty. |
|
|
Iterates over the next operation in the plan for each partition in the range given by the |
||
|
|
|
Retrieval of data from a remote database. |
|
|
|
Operation involving accessing values of a sequence. |
|
|
|
Retrieval of a single row that is the result of applying a group function to a group of selected rows. |
|
|
|
Operation sorting a set of rows to eliminate duplicates. |
|
|
|
Operation sorting a set of rows into groups for a query with a |
|
|
|
Operation sorting a set of rows before a merge-join. |
|
|
|
Operation sorting a set of rows for a query with an |
|
(These are access methods.) |
|
Retrieval of all rows from a table. |
|
|
|
Retrieval of sampled rows from a table. |
|
|
|
Retrieval of rows from a table based on a value of an indexed cluster key. |
|
|
|
Retrieval of rows from table based on hash cluster key value. |
|
|
|
Retrieval of rows from a table based on a rowid range. |
|
|
|
Retrieval of sampled rows from a table based on a rowid range. |
|
|
|
If the table rows are located using user-supplied rowids. |
|
|
|
If the table is nonpartitioned and rows are located using index(es). |
|
|
|
If the table is partitioned and rows are located using only global indexes. |
|
|
If the table is partitioned and rows are located using one or more local indexes and possibly some global indexes. |
|
|
The partition boundaries might have been computed by: A previous The |
||
|
|
|
Operation accepting two sets of rows and returns the union of the sets, eliminating duplicates. |
|
|
|
Operation performing a view's query and then returning the resulting rows to another operation. |
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

