CSCI-1080 Intro To CS: World Wide Web
Saint Louis University, Department of Computer Science
Collaborative Filtering
“Expert opinions” without the experts
Collaborative filtering (CF) is a common Web technique for generating personalized recommendations. Examples of its use include Amazon, Netflix, LastFM and StumbleUpon.
Thanks to collaborative filtering, a site like Amazon can say, “People who bought books A and B also bought book C.” Amazon needs no understanding of people or books to generate this recommendation. All Amazon needs is a database of who has bought what, so that it can calculate who are “people like you.” Then any time a “person like you” buys a book that you have not bought, Amazon can “personally” recommend that book to you.
Collaborative filtering needs no built-in subject knowledge to generate recommendations. Many other Web sites do rely on built-in expert subject knowledge to generate recommendations, and so do not use collaborative filtering. For example, Pandora hires music experts to listen to each song in its inventory. These experts code the “genome” of each song. Pandora then generates personalized recommendations by determining what musical “genes” each individual user likes and recommending songs with those “genes.”
Even less related to collaborative filtering are pseudo-personalized recommendations: “Thanks, MARK SMITH, for buying Web hosting from us. Add Identity-Protector to your shopping cart for just $10 per month.”
Tuples: content of CF
A tuple is an ordered list. The term tuple is used when the length of the ordered list and the type of element in each position of the ordered list are predetermined. We say n-tuple to signify a tuple of length n. Users establish a preference or a profile by associating a set with another set; for example a page, a keyword or a set of keywords with a topic or a product or with their social media profile. They create a tuple that then the CF algorithm uses to compute recommendations.
For example:
A graph such as 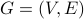 is a 2-tuple. It is an ordered list of length two. The first element of the ordered list is always a set of nodes. The second element of the ordered list is always a set of edges.
A path in a graph is an ordered list but would not normally be considered a tuple. Paths have many different lengths.
The combination of user, page, and tags of a bookmark in a CF website is a 3-tuple: (u,p,T) where
is a 2-tuple. It is an ordered list of length two. The first element of the ordered list is always a set of nodes. The second element of the ordered list is always a set of edges.
A path in a graph is an ordered list but would not normally be considered a tuple. Paths have many different lengths.
The combination of user, page, and tags of a bookmark in a CF website is a 3-tuple: (u,p,T) where
u = the user who created the bookmark
p = the page being bookmarked
T = the set of tags associated by that user with that page
Bipartite graphs: structure of CF
All a CF website needs is a database of which tags have been used to describe which pages. Collaborative filtering does the rest.
A graph can be used to represent which tags have been used to describe which pages. For example, in the graph below:
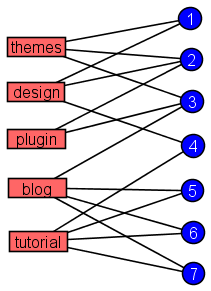 |
Each red rectangle represents a tag used (for example a keyword of interest for a song)
Each blue circle represents a page bookmarked (for example a song or a product)
A tag and a page are joined by an edge if that tag has been used to describe that item (page, product or song)
Because of the way it is constructed, the above graph has two notable properties:
Each node is colored with one of two colors (red or blue)
Each edge joins two nodes of different colors. (In other words, no two nodes of the same color are adjacent.)
This is an example of a bipartite graph. Another way to describe a bipartite graph is by drawing the red nodes on one side of the picture and the blue nodes on the other side of the picture, just as above. Then each edge crosses from the left side to the right side. No two nodes on the same side are adjacent.
Most graphs are non-bipartite. A graph is non-bipartite when there is:
No way to color its vertices red and blue without creating red-red or blue-blue edges
No way to draw its vertices in two columns so that edges only cross from column to column and never join vertices in the same column
Note that the above two conditions are both saying the same thing.
Structural equivalence: computation of CF
Finding clusters is one way to discover meaningful groups of nodes in a graph. Another way is based on the idea that nodes x and y are similar to the extent that they have similar network neighborhoods – even if x and y are not adjacent to each other. This is the idea behind structural equivalence.
We define the structural equivalence of two nodes x and y as the similarity of their neighborhoods, as measured by the Jaccard index:
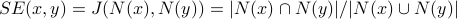 .
.
This equals 1 when x and y have identical neighborhoods and 0 when the neighborhoods of x and y have no nodes in common.
Example: Consider the bipartite graph drawn below. The yellow nodes below left are tags on delicious and the orange nodes below right are some of the URLs associated with these tags:
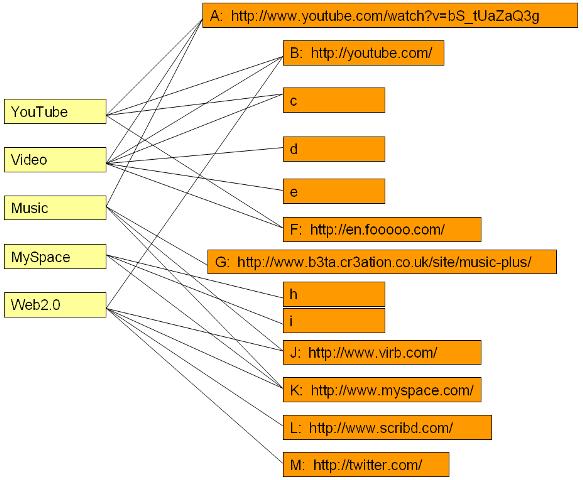 |
The structural equivalence of YouTube and Video is

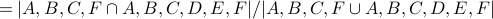
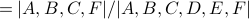
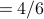
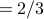
The structural equivalence of MySpace and Video is:
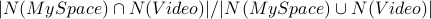
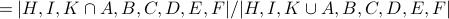
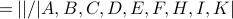
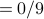
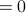
CF-Delicious: micro-synthetic summary
The content, structure, and computation discussed above give us a simple framework for an abbreviated impersonal version of collaborative filtering (adapted from Principia Cybernetica):
The two steps of impersonal collaborative filtering:
A large set of affiliation data is collected. For example, a set of 3-tuples defined above, from which we derive a bipartite graph indicating which tags are affiliated with which Web pages.
Given a tag of interest and the bipartite graph from step 1, structural equivalence is used to compute the similarity of other tags to that tag of interest. A subgroup of “Related Tags” is identified and presented in rank order.
The four steps of collaborative filtering
Imagine that you are a habitual Amazon customer. All you have to do is log in and you will see personalized recommendations informed by your history of purchases. The following four steps (again adapted from Principia Cybernetica) describe how this works.
The four steps of personalized collaborative filtering:
A large set of affiliation data is collected. For Amazon and most other CF sites, the relevant bipartite graph indicates which users have bought (downloaded, used, recommended, etc.) which items.
You log in. Given the bipartite graph from step 1, structural equivalence is used to compute the similarity of other users to you. A subgroup of “people like you” is identified.
Using the subgroup derived in step 2, an average preference function is determined. This function describes what “people like you” typically buy (download, etc.) on the site.
Using the preference function derived in step 3, the site displays the most preferred items that you have not yet bought.
The contect of this site is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.